PDF Extraction with Microsoft Agent Framework and F#
TL;DR
- Creating and orchestrating agent workflows using local or remote LLMs in .NET is easy with Microsoft Agent Framework
- Extracting, storing and searching document info is a challenging problem to tackle (particularly PDFs!)
- The OpenAI Responses API in Azure AI Foundry provides enterprise grade access to frontier models
Introduction
I recently took on a challenging but tractable task.
The question, at least on the surface, was simple - can I use AI to speed up the time consuming, manual process of looking through heterogeneous documents to pick out the values and terms for manual entry?
This kind of problem is a great use case for LLMs / v(ision) LLMs as it leans into their strengths - understanding the context of a document. It is also something for which it would be extremely difficult, if not impossible, to program a robust manual routine - the variation in layout and content of the documents is just too vast.
Getting started
Throughout 2025 we’ve seen the tools and capabilities of models and frameworks develop rapidly. It can feel a bit overwhelming and hard to know where to start.
I began by breaking the task into a series of questions:
- How can I access LLMs for inference?
- What APIs are available?
- How do I configure their behaviour?
- How do I pass them data?
- How do I know they are working correctly?
Answering them has led me to explore the ecosystems and tooling available, which were surprisingly accessible and intuitive once I got hands-on with them.
How to access LLMs?
Perhaps the most obvious first question was “Where can I access LLMs for experimentation?”.
We can choose to run them locally or remotely.
I am lucky enough to have a pretty capable PC which can run many of the open source models you can find on platforms such as Hugging Face and I figured “If I can get it working on a small, local model then a large, remote model should have no problem and I won’t be relying on brute force intelligence over a poor solution.”. It also has the advantage of being free, other than the power.
I did briefly experiment with Ollama along with OpenWebUI for local model hosting and configuration, but I ultimately preferred the experience of using LM Studio so settled on this as my platform. It has a simple setup process and an intuitive interface which makes discovering, installing and experimenting with models a breeze.
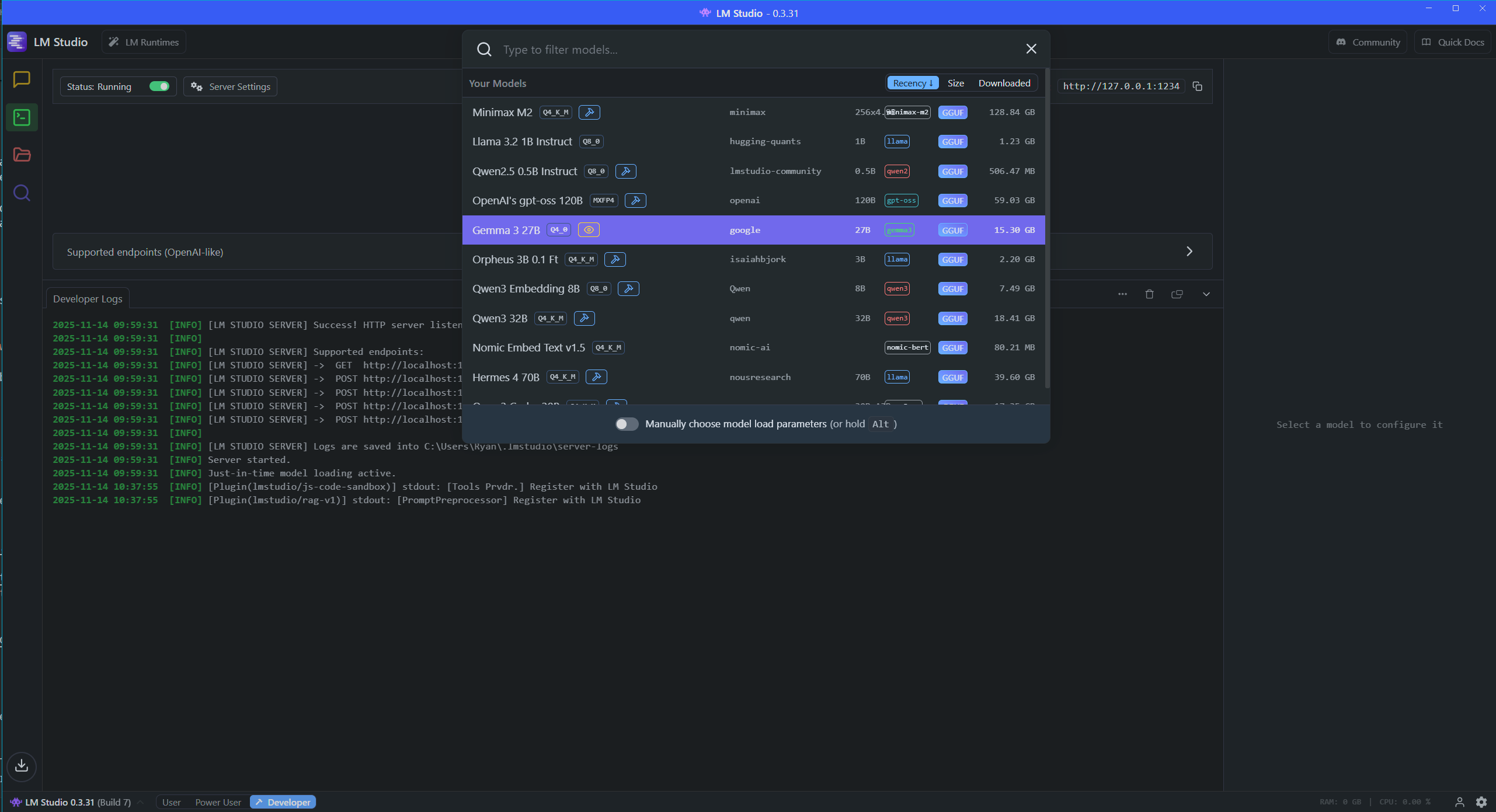
For the upcoming experiments I needed models which supported vision, reasoning and tool use.
I did a quick run of experiments against the top vision models available in LM Studio and found the best results with Gemma 3 27B.
Gemma 3 was also great at reasoning and ok with tool use, however I also had strong results for these use cases with Qwen3 32B.
Since then many other models have been released, such as OpenAI’s GPT OSS 120B which is much more resource intensive but can still be run on a high-end home PC.
Microsoft Agent Framework (and Semantic Kernel)
Although a .NET developer by trade, I often turn to Python when working with ML / AI projects. For this project however, I decided see what Microsoft had available. This would facilitate integration with our existing F# / Azure stack.
They had an array of overlapping products and services pitched at various levels of abstraction. Many of them were in preview and only partially documented.
At the time I started the project, the framework which formed the core of the stack was Semantic Kernel.
This has been around for a while and had recently spawned its Agent Framework which embraced the building blocks famously laid out in Anthropic’s Building Effective Agents paper.
As I progressed through the project, the new Microsoft Agent Framework was announced as a replacement for Semantic Kernel and AutoGen.
Whilst this did initially bring to mind the famous XKCD on Standards, it has allowed the teams to merge in order to work on a unified, modern platform.
I’ve since ported all my Semantic Kernel code across to Microsoft Agent Framework and the new API is generally much nicer, although still in preview. The devs are really active and helpful with issues on Github.
There is an awesome series of videos on YouTube which show practical examples of the migration process from SK and how to use all the features of the new framework. I’d highly recommend it as your first point of call for more information on the approaches discussed in this blog.
How to get data out of PDFs?
PDF is a notoriously difficult format to work with. It is more of an image than a document, although it has elements of both.
My first instinct was to try to extract the text from the document.
I found a richly featured library called PDFPig which supports text extraction from PDFs in .NET. It uses a number of algorithms to determine the arrangement of the text and chunk it along with x/y coordinates determining its position on the page.
I wrapped its output in some descriptive tags to hint the structure to the model.
let pageBlocksFromPdf filePath =
use document = PdfDocument.Open filePath
document.GetPages()
|> Seq.map (fun page ->
page.Letters
|> NearestNeighbourWordExtractor.Instance.GetWords
|> DocstrumBoundingBoxes.Instance.GetBlocks
|> UnsupervisedReadingOrderDetector.Instance.Get
|> Seq.map (fun block -> $"<BLOCK x=%0.3f{block.BoundingBox.TopLeft.X} y=%0.3f{block.BoundingBox.TopLeft.Y} w=%0.3f{block.BoundingBox.Width} h=%0.3f{block.BoundingBox.Height}>\n{block.Text}\n</BLOCK>")
|> String.concat "\n")
|> String.concat "\n<PAGE>\n"
|> fun allText ->
$"<PAGE>\n{allText}\n"
As effective as the library was, I found that the sheer volume of data quickly exceeded the context length of the LM Studio models on my machine.
Retrieval Augmented Generation (RAG)
The excessive size of the complete document content overflowing the context led to me experimenting with Retrieval Augmented Generation (RAG). This is just a fancy name for storing data in a database, usually with vector embedding support, and searching for relevant information when needed rather than trying to cram it all into the model’s short term memory.
An embedding is essentially a numerical representation of the ‘meaning’ of an item of data, allowing you to understand how it relates to other items.
Semantic Kernel provides a ‘connector’ for a vector database called Qdrant which simplifies interacting with an instance.
You can launch Qdrant easily using Docker Compose:
services:
qdrant:
image: qdrant/qdrant:latest
container_name: qdrant
ports:
- "6333:6333"
- "6334:6334"
volumes:
- qdrant_storage:/qdrant/storage
restart: unless-stopped
volumes:
qdrant_storage:
driver: local
I manually serialised the extracted document chunks and posted them to the LM Studio embedding endpoint to get their vectors.
A DTO model was defined with attributes from Microsoft.Extensions.VectorData identifying the primary key, data and the embedding fields which allowed data to be inserted into the Qdrant store and subsequently queried and rehydrated.
type DocumentBlock() =
[<VectorStoreKey>]
member val Id: Guid = Guid.Empty with get, set
[<VectorStoreData(IsIndexed = true)>]
member val DocumentId: string = "" with get, set
[<VectorStoreData(IsIndexed = true)>]
member val Page: int = 0 with get, set
[<VectorStoreData(IsIndexed = false)>]
member val Text: string = "" with get, set
[<VectorStoreVector(Dimensions = 768, DistanceFunction = DistanceFunction.CosineSimilarity, IndexKind = IndexKind.Hnsw)>]
member val TextEmbedding: ReadOnlyMemory<float32> = ReadOnlyMemory.Empty with get, set
// ....
pdfPath
|> embeddedBlocksFromPdf
|> collection.UpsertAsync
With all this set up I could embed a query and then search Qdrant for document chunks which are related to it.
This approach dramatically reduces the amount of data needed by the contract extraction LLM, as in theory you have filtered for relevant information. It could also, again theoretically, improve the quality of results as you have kept the LLM’s attention on the important stuff.
let embeddedQuery = embedQuery "What is the notional amount of the swap?"
collection.SearchAsync(embeddedQuery, 5)
|> AsyncSeq.ofAsyncEnum
|> AsyncSeq.iter (fun result -> printfn $"{result.Score} : {result.Record.Text}")
Agentic Search
Initial tests showed some success, but naturally led to the question “How many results should I ask the vector database for?”. Too few and you might not get the info you need, and too many will inflate the context length and add noisy information, diluting what’s important and arguably defeating the point of implementing the search.
One answer to this is rather than search for the chunks ourselves, give the LLM a tool which allows it to search the store for itself and instruct it to keep searching until it finds what it needs. Semantic Kernel makes this easy by passing the Qdrant store to an instance of their VectorStoreTextSearch plugin which can then be registered as a tool for the LLM.
I also sped up the process of embedding the documents by implementing an IEmbeddingGenerator tailored to the LM Studio embedding API. By passing this to the Qdrant connector the embeddings would be automatically requested and populated when inserting an item, removing the need for me to manually request them from LM Studio.
type ExtractedDocument() =
[<VectorStoreKey>]
[<TextSearchResultName>]
member val Id: Guid = Guid.Empty with get, set
[<VectorStoreData(IsIndexed = false)>]
[<TextSearchResultValue>]
member val Extract: string = "" with get, set
[<VectorStoreVector(768)>]
member this.ExtractEmbedding: string = this.Extract
//...
let vectorStoreEmbeddings =
pageChunks
|> Array.map (fun (pageNumber, docChunk) ->
ExtractedDocument(
Id = Guid.NewGuid(),
Extract = JsonSerializer.Serialize docChunk))
let vectorStore =
QdrantVectorStore(
new QdrantClient("localhost"),
ownsClient = true,
options = QdrantVectorStoreOptions(EmbeddingGenerator=lmsEmbeddingGenerator))
let collection = vectorStore.GetCollection<Guid, ExtractedDocument>("extracted-documents")
collection.EnsureCollectionExistsAsync()
vectorStoreEmbeddings
|> collection.UpsertAsync
At the time I found Qwen 3 was the most consistently successful at using the tool.
Vision!
After playing with the text extraction for a while with mixed results, a thought came to me - maybe I can just show a vision model pictures of the document?
That would give it the text information along with all the important visual clues as to how the blocks relate. I could ask it to extract, label and summarise the information for me. Surely that was too much for a tiny local model?
I converted a contract to a series of PNGs, prepared them as ImageContent for a chat message and sent them to Gemma 3. I was amazed when, after a few tweaks to the prompt, the document chunks it returned performed better with the agentic search than any of my raw text-based runs.
Inspection of the chunks in the vector store showed that they were mostly well extracted, labelled and described.
To further speed up the chunk extraction process I added two new features:
- Automation of the PDF -> Image sequence conversion with PDFtoImage
- Exposing of the Qdrant
upsertcode as a tool for the vllm.
In Semantic Kernel this was achieved by decorating a method with the KernelFunction attribute. In Microsoft Agent Framework you wrap a static method in
AIFunctionFactory.Create().
type StoragePlugin(qdrantCollection:QdrantCollection<Guid, ExtractedDocument>) =
[<KernelFunction; Description("Store document chunks in the Qdrant vector database.")>]
member this.StoreDocChunks (docChunks : DocChunks) =
task {
do! qdrantCollection.EnsureCollectionExistsAsync()
let vectorStoreEmbeddings =
docChunks.Chunks
|> Array.map (fun (docChunk) ->
ExtractedDocument(
Id = Guid.NewGuid(),
Extract = JsonSerializer.Serialize(docChunk)))
return!
vectorStoreEmbeddings
|> qdrantCollection.UpsertAsync
}
Combined with the IEmbeddingGenerator, this allowed the agent to extract, embed and save the chunks autonomously.
Search Orchestration
In the previous example I had two agents, the document-chunk-extracting vision agent and the contract-extracting reasoning agent with chunk search capabilities. They were run sequentially, which is one pattern of agent orchestration.
The links here are to the Semantic Kernel docs I used, but the functionality is being added to Microsoft Agent Framework too.
It was here that I hit a fairly common issue. In normal circumstances you can’t combine tool use and structured output when calling an agent. This is simply because forcing a JSON schema on the output prevents the agent calling tools.
There are various slightly hacky workarounds, such as having a ‘thinking output’ field on your structured model. Another, which I tried here, is giving the agent a ‘validation’ tool with your model as structured input and which just returns it unchanged. You can then ask the agent to call it before returning the output.
This worked sometimes, but I would often need to ask the model to try searching for more info before trying again. This was a perfect opportunity to experiment with another common orchestration pattern, Group Chat.
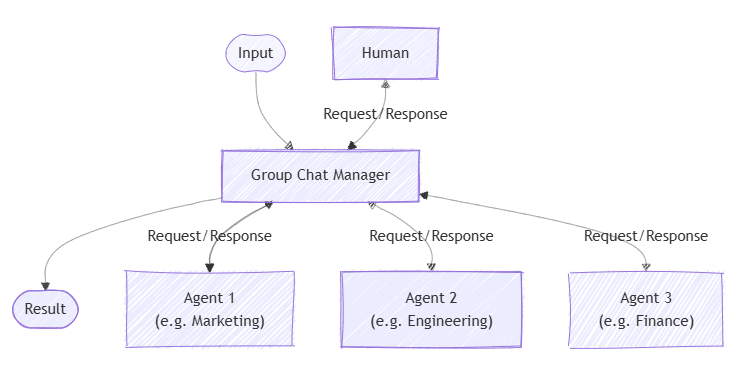
More concretely, I would create an agent to act in my place as a ‘critic’ to the contract ‘author’. These can be different LLMs from different providers - it’s all abstracted away by the framework.
The critic was instructed to either provide constructive feedback as to what was missing or utter the magic phrase I approve. The group chat orchestration requires a GroupChatManager. I re-implemented the sealed AuthorCriticManager class, which is itself a subclass of RoundRobinGroupChatManager with two simple overloads:
FilterResultsfilters for messages by the authorShouldTerminatelooks for the magicI approveexit phrase (or reaching theMaximumInvocationCountspecified on theGroupChatManager).
type AuthorCriticManager(authorName: string, criticName: string) =
inherit RoundRobinGroupChatManager()
override this.FilterResults(history: ChatHistory, cancellationToken: CancellationToken) =
let finalResult =
history
|> Seq.filter (fun message -> message.AuthorName = authorName)
|> Seq.last
let result = GroupChatManagerResult<string>(finalResult.ToString(), Reason = "The approved copy.")
ValueTask.FromResult(result)
override this.ShouldTerminate(history: ChatHistory, cancellationToken: CancellationToken) =
let baseResult = base.ShouldTerminate(history, cancellationToken)
task {
// Has the maximum invocation count been reached?
let! baseResult = baseResult.AsTask()
if not baseResult.Value then
// If not, check if the reviewer has approved the copy.
let lastMessage = history |> Seq.tryLast
match lastMessage with
| Some msg when
msg.AuthorName = criticName &&
msg.ToString().Contains("I Approve", StringComparison.OrdinalIgnoreCase) ->
// If the reviewer approves, we terminate the chat.
return GroupChatManagerResult<bool>(true, Reason = "The reviewer has approved the copy.")
| _ ->
return baseResult
else
return baseResult
} |> ValueTask<GroupChatManagerResult<bool>>
This worked pretty well, and on average improved the results. It was funny to watch the models go back and forth in their conversation, although perhaps due to their tiny local nature they often ended up in extended dialogue which wasn’t going anywhere. In these cases I was glad I wasn’t paying for the tokens (although of course I could have limited the MaximumInvocationCount as stated above).
Cloud Models
At this point I had explored the SDKs, APIs, orchestrations, tools and discovered approaches that worked most of the time with small local models. It seemed an appropriate time to explore larger, commercial models to see what they could achieve and also what challenges might be involved.
I had noticed the recently released Github Models service which allows you to experiment with a large selection of models for free with restrictions or derestricted with billing linked to your Github account. This seemed like a low barrier to entry, plus the AI Toolkit plugin in VSCode made it easy to explore the catalogue:

I decided to start with the simplest thing that could possibly work, on the smallest model available (within reason, given cost vs performance etc etc). Could GPT-5 mini use its vision capabilities to extract the entire contract in one shot from the images alone, negating the need for any extraction / chunking / RAG / tools / orchestration etc?
I had to turn on billing as the multiple page images exceeded the free limits on context size, but to my delight the model was correct on every field. I tried it with a different contract type and again it was correct. This was of course great news as it meant we needed to use very few tokens compared to the more complex approaches, plus there was less to maintain and equally less to go wrong.
Responses API
Whilst looking at the OpenAPI documentation, I found a section explaining that you can upload PDFs directly! Open API extracts both images and text from the document and feeds it to the model for you. This would simplify my code and provide even more context to the model, a double win.
There was only one problem - PDF upload requires use of the Responses API. This is OpenAI’s most up to date API, replacing the (still widely used) ChatCompletions and Assistants APIs which came before it. Unfortunately, Github Models only supports the Chat Completions API. In addition to this, I had been authenticating with a Personal Access Token which was fine for testing but not an ideal solution as we moved towards production.
For both of these reasons, I decided to look at Microsoft’s AI Foundry enterprise offering. This both supports the Responses API and allows authenticating with Azure credentials. It’s also tied into the billing for the rest of our Azure services and has full featured VSCode integration, so acted as a great replacement for Github Models.
Once I provisioned the GPT 5 mini model in AI Foundry and switched my connection details, I was able to create an OpenAIResponseClient and directly submit a PDF as a byte array inside a DataContent message. I once again found very strong performance, with the simple architecture resulting in a low token count and very reasonable cost of a fraction of a penny per document.
let pdfToChatMessage (pdfBytes : byte[]) =
let content = ResizeArray<AIContent>()
DataContent(pdfBytes, "application/pdf") |> content.Add
ChatMessage(ChatRole.User, content)
let tryExtractDocument (options : AgentFrameworkOptions) (docData : DocumentData) = async {
let azureOpenAIClient = new AzureOpenAIClient(Uri options.ServerUrl, AzureCliCredential())
let responseClient = azureOpenAIClient.GetOpenAIResponseClient options.Model
let pdfMessage = pdfToChatMessage docData.Data
let agent = contractExtractionAgent responseClient
let! response = agent.RunAsync pdfMessage |> Async.AwaitTask
return response.Deserialize<Contract> JsonSerializerOptions.Web
}
Conclusion
It’s never been easier to get up and running with your own agent-based software. There are powerful small models and orchestration frameworks, convenient local tooling and cheap cloud hosting options that allow you to go from idea to prototype in no time. With that said, there are so many options and ways of tackling the problem that it can feel overwhelming. That’s before you even consider how quickly the ecosystem is developing and changing underneath you.
In these situations, as in most other software development challenges, I find the best approach is to try to balance exploration and exploitation, understanding the landscape and making meaningful progress towards your goals. Focus on the activities which will resolve the most amount of uncertainty for the least amount of risk, then take the simplest path possible given what you’ve learnt.
Of course, a working demo is only the start of the journey. Following on, you need to consider e.g.
- How will I expose the functionality to users?
- How will I monitor output quality?
I would recommend checking out the AI Engineer channel on Youtube, particularly the videos which cover evals, once you are ready to move beyond the proof of concept stage.